Abstract
This work aims at a challenging task: human action-reaction synthesis, i.e., generating human reactions
conditioned on the action sequence of another person. Currently, autoregressive modeling approaches with
vector quantization (VQ) have achieved remarkable performance in motion generation tasks. However, VQ has
inherent disadvantages, including quantization information loss, low codebook utilization, etc. In addition,
while dividing the body into separate units can be beneficial, the computational complexity needs to be
considered. Also, the importance of mutual perception among units is often neglected. In this work, we
propose MARRS, a novel framework designed to generate coordinated and fine-grained reaction motions using
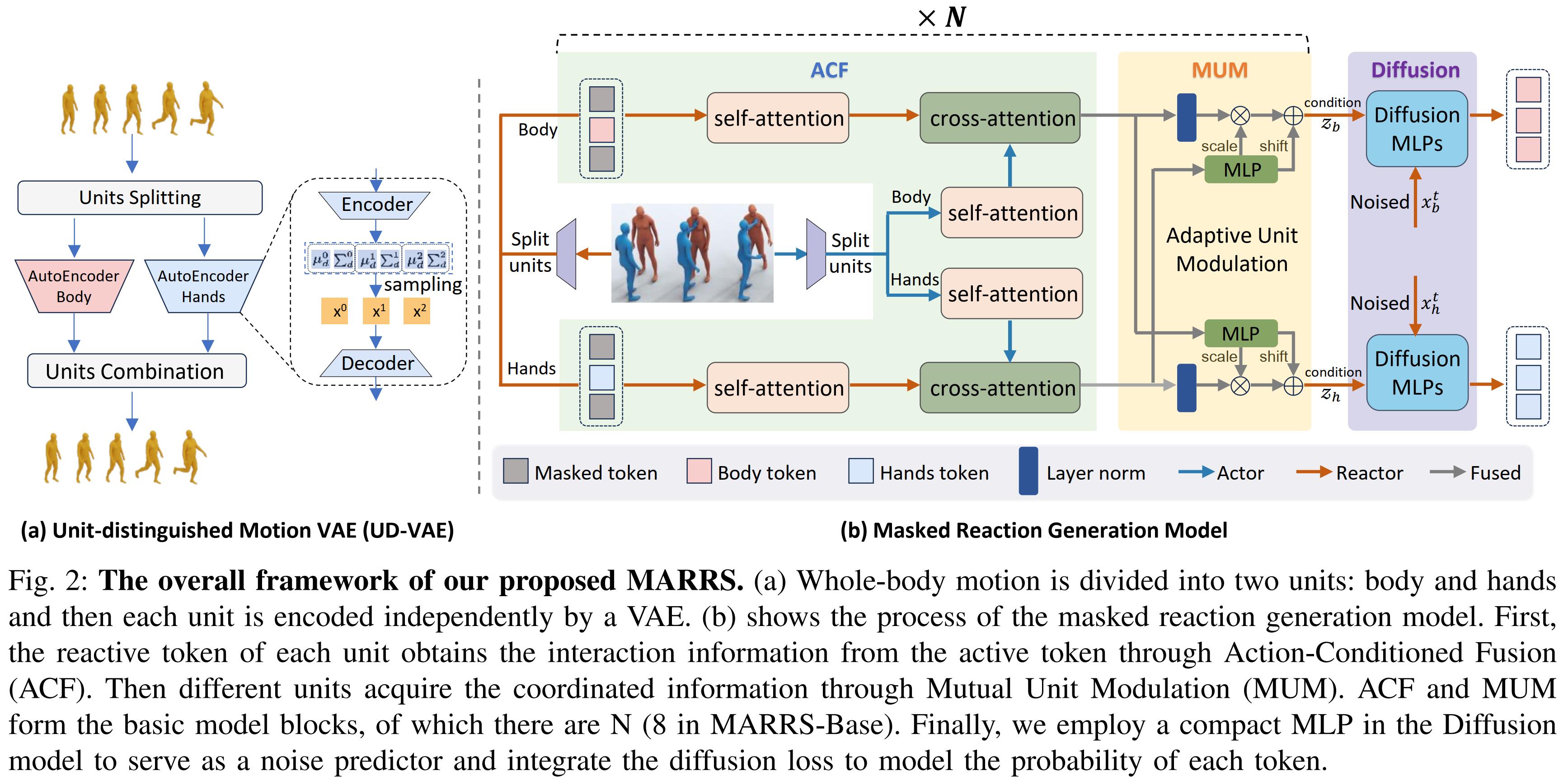
continuous representations. Initially, we present the Unit-distinguished Motion Variational AutoEncoder
(UD-VAE), which segments the entire body into distinct body and hand units, encoding each independently.
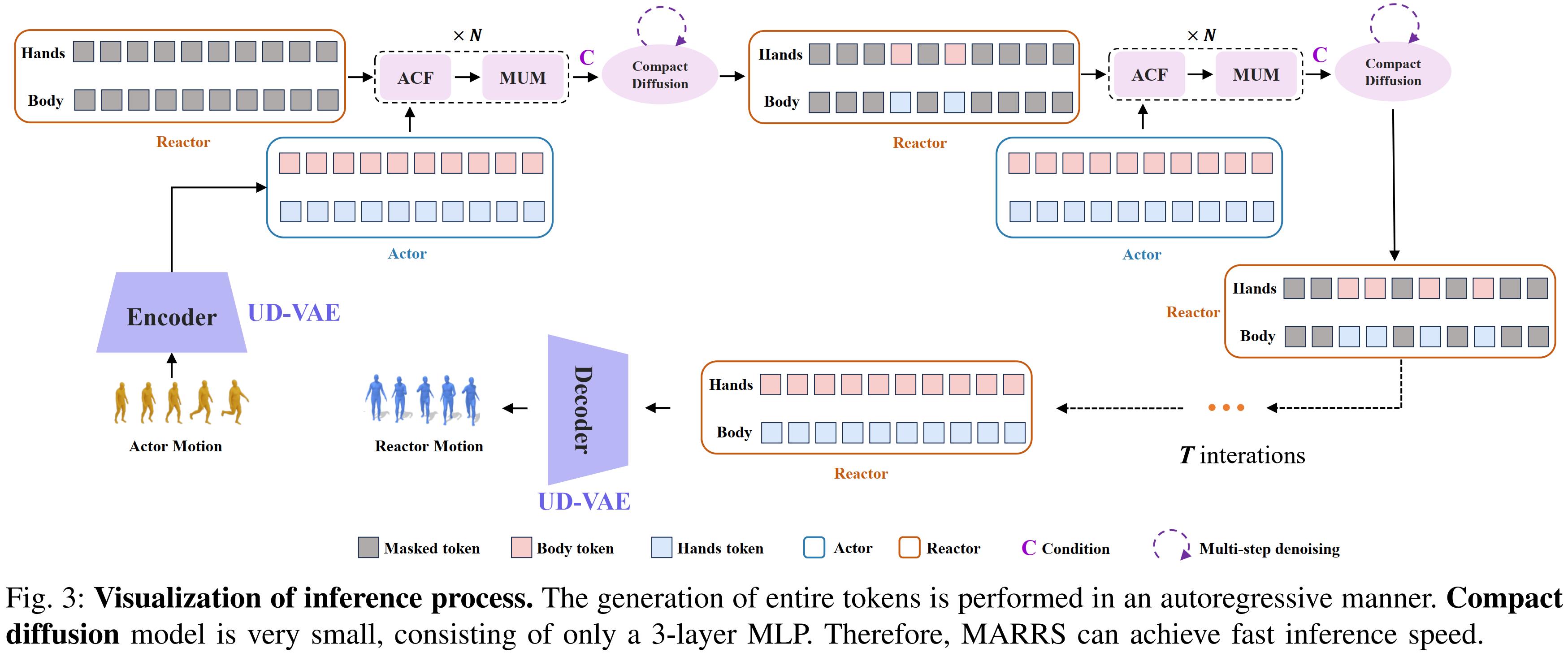
Subsequently, we propose Action-Conditioned Fusion (ACF), which involves randomly masking a subset of
reactive tokens and extracting specific information about the body and hands from the active tokens.
Furthermore, we introduce Mutual Unit Modulation (MUM) to facilitate interaction between body and hand units
by using the information from one unit to adaptively modulate the other. Finally, for the diffusion model,
we employ a compact MLP as a noise predictor for each distinct body unit and incorporate the diffusion loss
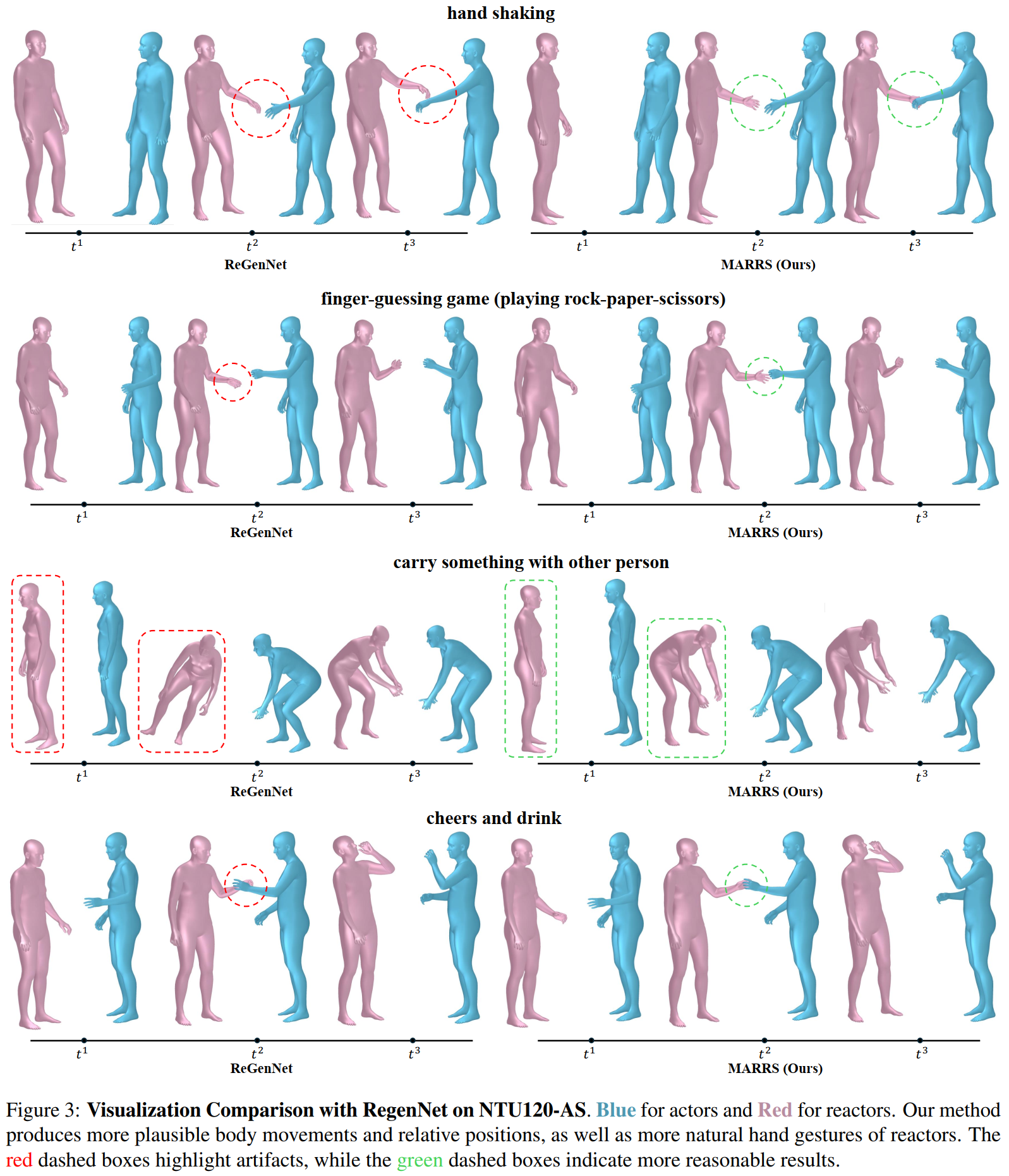
to model the probability distribution of each token. Both quantitative and qualitative results demonstrate
that our method achieves superior performance. The code will be released upon acceptance.